GraphQL as an extension of Conway’s Law
Posted on Dec 6th, 2019 in GraphQL
“Organizations which design systems … are constrained to produce designs which are copies of the communication structures of these organizations.” – Melvin Conway
In October, I went to the GraphQL summit in San Francisco. One of the biggest topics I was interested in was federation. This is a relatively new concept (the whole idea has only been around for a few months), and so I was curious to see how this was achieved without using the full Apollo suite. While I didn’t find a great answer (which was basically you’ll have to write it yourself), I did find a lot of people new to the idea of federation and why we would want to run something seeming so complex.
For those who don’t know, Schema federation is essentially a way to compose multiple downstream GraphQL services into a single GraphQL api. It differs from Schema Stitching primarily by being much more declarative. One team of API developers can use GraphQL directives and types to say how their data is related to another team’s graph. The stitching is also fully managed by a gateway that is aware of downstream APIs and builds its own Schema based on this without writing any code. When you have multiple teams and services using a unified graph, you need a way to represent it in a holistic way and managing a single GraphQL api quickly becomes un-obtainable.
A brief primer on Conway’s Law
Conway’s law simply states that "Organizations are constrained to produce designs that follow the communication structures of the organization." This idea has been studied over and over again and there is quite a bit of research that supports it, and its impacts range from API design to Product UX. For example, in 1997 Nigel Bevan published a paper that argued that websites are structured in a way that matches the internal organizational concerns, causing a frictitous user experience.
The driving factor behind Conway’s Law is that when you are communicating between other business units in order to get your job done (or help them get their job done), then a natural contract between your work and their work develops. Perhaps you expose some data for this other team to expose, perhaps they do the same for you. Maybe you re-write one of your services to accept input from that team. Either way, it quickly becomes apparent that you are developing a contract with another team, whether you are explicitly (IE through microservices and strong contracts) or implicitly (through a shared database) doing it. Or to put it in Mel Conway’s Own words own words: "[Conway’s Law] is a consequence of the fact that two software modules A and B cannot interface correctly with each other unless the designer and implementer of A communicates with the designer and implementer of B. Thus the interface structure of a software system necessarily will show a congruence with the social structure of the organization that produced it."
One of the reactions to Conway’s law was (and still is) the rise of small autonomous teams that are responsible for their data. This forces engineers think more carefully and thoughtfully about these communication lines. The team separation causes a clear distinction on where those lines should and must be drawn.
With that in mind, take a look at this image:
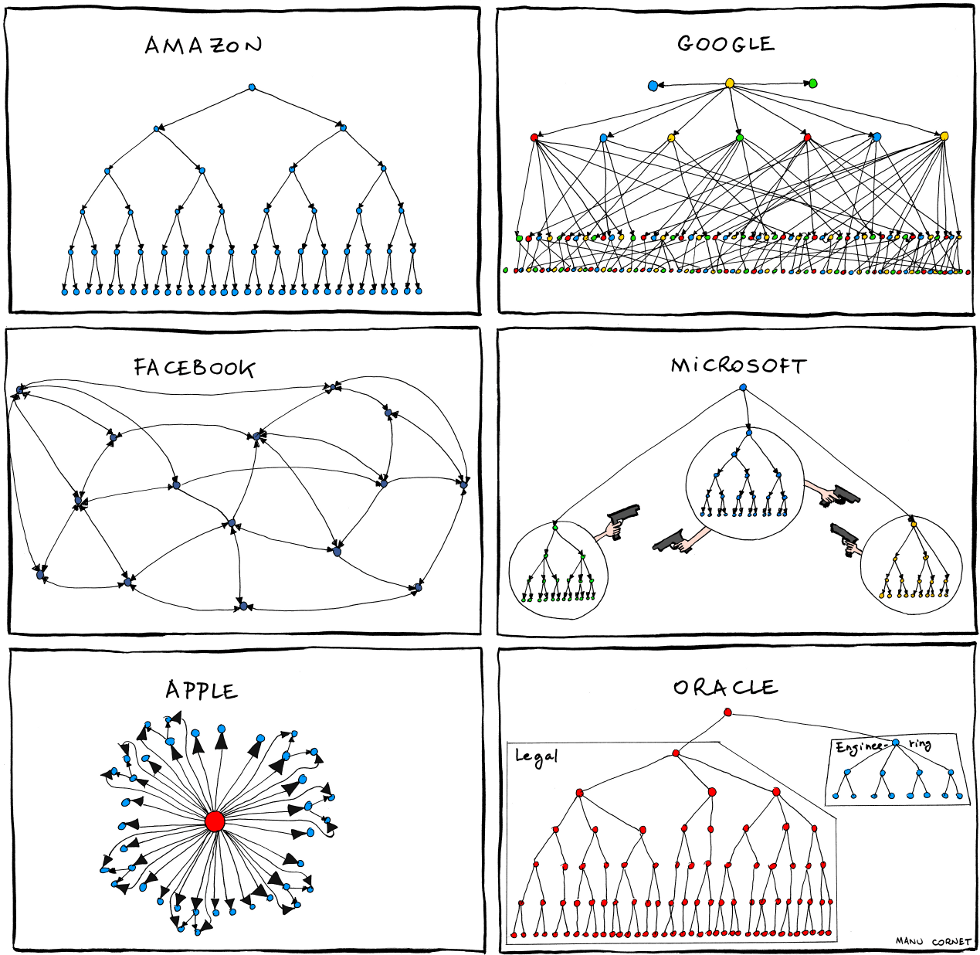
This image may be tongue in cheek, but it illustrates what I am getting at: Organizational structures are just large graphs, with the lines of communication being the edges that connect the teams, or nodes. So if your services follow your communication structures, they will inevitably start coalescing towards a graph like structure. Which is why GraphQL is a natural fit for organizations.
The problems GraphQL solve
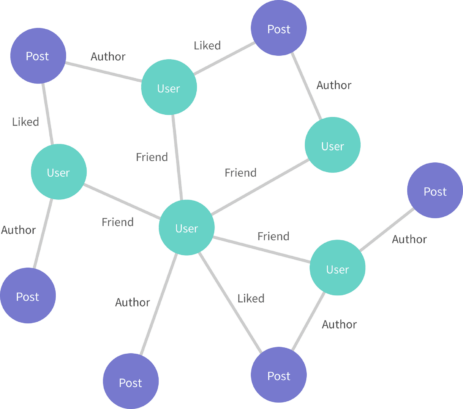
The biggest problem that GraphQL sought out to solve is the relationship sprawl that plagues RESTful APIs and the stitching between them that most major frontends already. If you look at a wordpress API response, you’ll notice that there is an object that contains references to other endpoints to grab other pieces of data from the api.
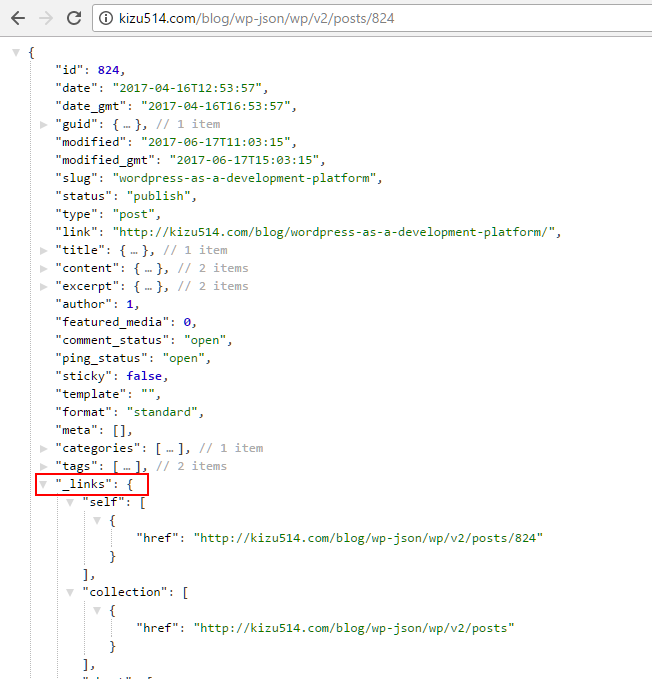
This helps the API be discoverable. This allows clients to visit a single endpoint of some api and "discover" other capabilities of the API by crawling. Many big APIs model their responses this way, not just wordpress. There a few API specs around developing your APIs around this idea as well, like HATEOS, JSON HAL, and JSON API to name a few.
Facebook’s API is modeled like this. When you got a person’s profile from it, you wouldn’t get full objects of their friends, instead you would get links to were to get the full object of their friends. This is the world in which graphQL was invented.
Instead of making developers have to get a full API response in order to get links to other resources and then stitch that data together, graphQL is meant to be the layer that allows you to query over those relationships and represent them in a way that makes sense.
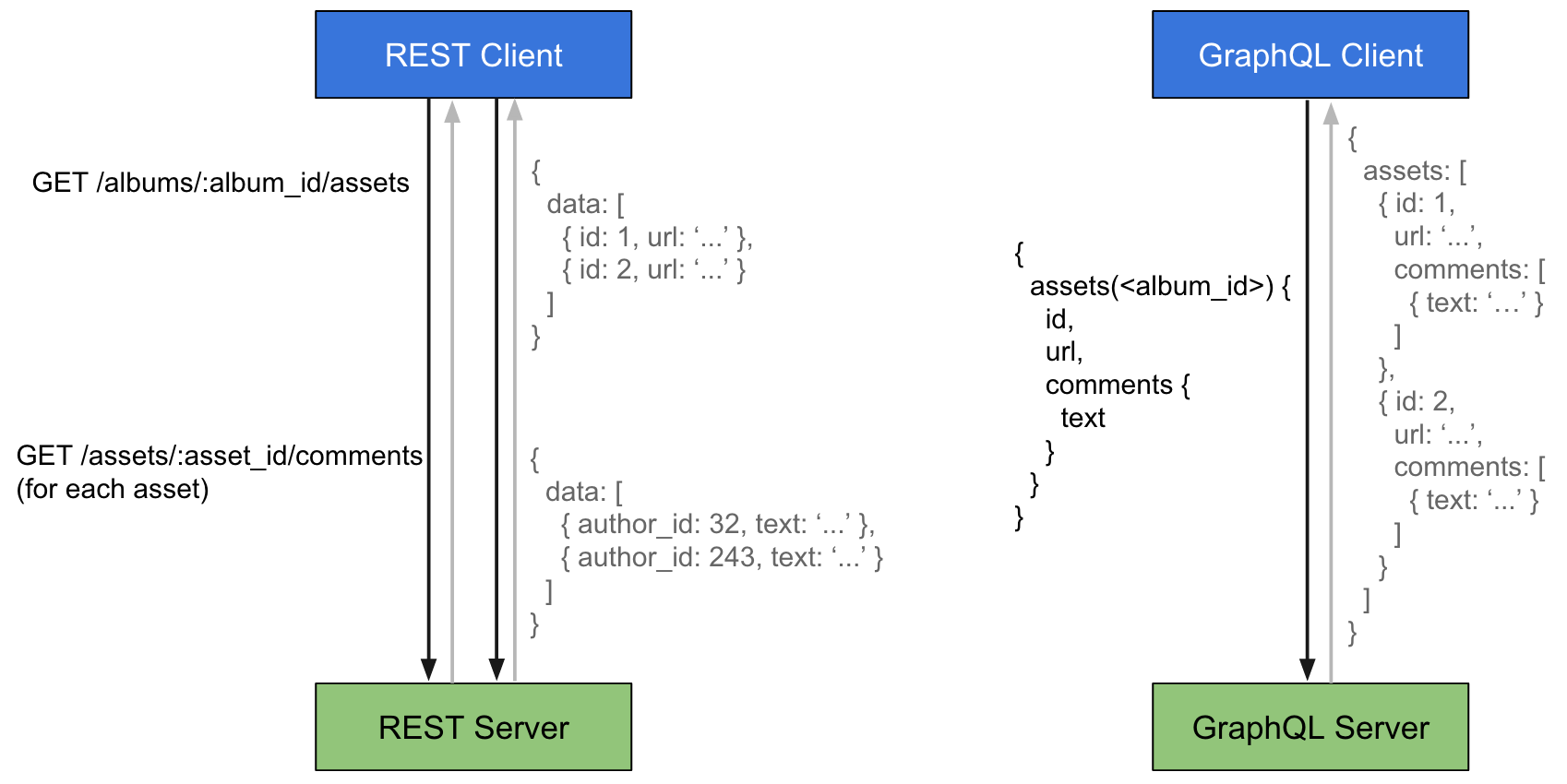
.
How GraphQL fits in with Conway’s Law
If you develop software that mirrors your communication structures, and your communication structures are typically graphs, then it stands to reason that you can represent your communication via GraphQL using relationships to represent needs between teams and nodes being the data team is responsible for. The more nodes that are on this graph, the easier it is for others to discover the technical capabilities of your organization.
So then it makes sense to have a single GraphQL implementation. But without federation, this requires a centralized team that manages a graphql schema stitching organization, which means you are introducing a central node in your graph. This central teams needs to manage deployments, schema collisions, tooling, and more. If that team falls ill or (as it happens in many organizations) doesn’t exist, then the code quality degrades to the point where you are having frequent outages and massive amounts of rework.
With federation on the other hand, you keep your stitching layer as dumb as possible. It is responsible for knowing where to get pieces of your schema and where to send requests, and it does this automatically when you register your services. Each team is responsible for maintaining their piece of the schema, which is their way of communicating out their capabilities. Each team can even extend the schema of another team without needing to touch their schemas or services.
Bigger Graphs Lead to More autonomous teams
As your graph becomes richer, the capabilities of the organization become much more apparent. The lift to bring in multiple data points from different sources on a single page, or a brand new app, is greatly reduced because you have a single API that provides all the data from different sources. Leveraging federation, you allow your graph to grow richer while also allowing your teams to remain autonomous with their own release cadence, processes and timelines.
Do I think that federation is right for everyone? Absolutely not. Federation, and by extension the issues it solves in regards to Conway’s Law, only really help when you are having pain coordinating teams. In most situations, this starts to happen when you either have a bunch of microservices, or you have a large team. For teams that follow the two pizza rule (no team should be so large that two pizzas can’t feed them; around 6 developers), federation if definitely overkill. However, when you have 10 two pizza teams, each managing at least two services, stitching together a schema for all of those teams and services becomes an operational burden, and this is where federation really shines.