Completely Useless Fun Project: Building The Parser
Posted on Nov 18th, 2018 in Compilers
Last week, we learned about the history of the compiler and about the lexer. This week we are talking about parsing.
It’s been awhile but I’m ready to get back into it. I was traveling pretty extensively for thanksgiving and didn’t have that much time in front of my computer. I hope everyone had a great thanksgiving!
Anyway, we already spoke about the history, design and implementing a lexer. This post is going to focus on building the parser.
Lexing, as we gathered a few weeks ago, is the lexical analysis part of the compiler. This is the process of deciding what each stream of characters mean. Are these characters some number? Are they a reserved keyword? Are the a variable name? The lexer will determine this.
The next part of the compiler, is syntactic analysis. This is what the parser does, analyze the syntax of your language. This is different than analyzing the semantics of your language, however, and that is what we will talk about next time.
Parsing a language
In order to parse a language, you must first take into account grammar. Grammar is the set of rules that make up valid statements (often referred to as the alphabet) in a language. This is how a compiler knows that 1 + 1 is valid, while knowing 1 + + 1 is not. It is important to know that a grammar does not know the meaning of a string, only the form it may take. The job of determining the meaning of the string comes from semantic parsing, which we will cover next week.
There are many different types of grammars, defined by noted linguist Noam Chomsky. These include regular, context-free, context-sensitive, and recursively enumerable. We actually spoke a little bit about regular grammars. Regular grammars are what powers Regular Expressions!
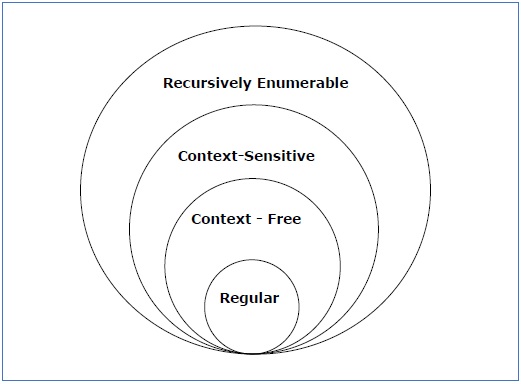
You may be wondering why we can’t use regular expression as our parser for building the entire programming language. The answer is not that simple. For simple languages a regular grammar may be good enough. But for more complex languages, regular grammars are hard to work with. This is because Regular grammars are either right-left or left-right (aka linear) whereas a grammar like context-free (which is what we will use to build Arbor’s parser) can basically be any combination of symbols.
Context Free Grammars
Context Free Grammars are the backbone of parsing a language. A Context Free Grammar is a set of production rules that describe all possible strings in a given language. These production rules are simple replacements and take the form B -> ß. This rule means that when you encounter a B replace it with a ß.
You can make a whole bunch of rules for a Context-Free-Grammar (CFG). The beauty of it is that these can literally go on for ever. Take the following Grammar for example:
A -> aA
A -> a
B -> b
B -> bB
S -> ABThis languages could take any string with all as first and all bs last. This takes abbbbbbbbbbbbbbbbbbbbbbbbbb as well as aaaaaaaaaaaaabbbbbbbbbb. When the parser encounters an a it replaces it with an A, so now a string like aaabbb becomes aaAbbb. Next it sees aA and replaces that with A so the string becomes aAbbb. This is performed one more time so that it becomes Abbb. Then, we do the same thing to the bs: Abbb -> AbbB -> AbB -> AB. Next we recognize that AB can be reduced to S and so AB becomes S. And S is our starting symbol and so we are done.
Using this, we can define a simple grammar that can perform any arithmetic operation:
S -> math
math -> math '+' math
math -> math '-' math
math -> math '*' math
math -> math '/' math
math -> NUMBERSo here we define NUMBER as any number, integer, or float. It is in all caps to show that it is not a grammar rule (non-terminal symbol), but a terminal symbol. A Non-Terminal Symbol is a symbol that can be reduced into a form that is a group of terminal symbols. Terminal symbols are the building blocks of the language. These are the lexemes you defined in the lexer. In other words, non-terminal symbols can be reduced to other symbols, either terminal or otherwise, while terminal symbols can not.
In our grammar, NUMBER is the end of the road. We can’t reduce it to anything else. 1 is 1. It won’t become math.
Now is this grammar valid? A simple test says yes: 1 + 2 * 3 - 8 + 66 / 3 * 4 is valid as well as 1 + 2. Let’s see why, using 1 + 2 * 3 - 8 + 66 / 3 * 4 as an example.
If we run 1 + 2 * 3 - 8 + 66 / 3 * 4 through our lexer, the string becomes NUMBER + NUMBER * NUMBER - NUMBER + NUMBER / NUMBER * NUMBER. One of our rules says that math can become a NUMBER so there we go. The parser turns the string into math + math * math - math + math / math * math. Then the arithmetic rules come into play: we can reduce math + math to math, so math + math * math - math + math / math * math becomes math * math - math + math / math * math. We can do that for every rule in that string: math * math - math + math / math * math -> math - math + math / math * math -> math + math / math * math -> math / math * math -> math * math -> math. And we are done. That was a valid string.
Of course none of this really helps because it looks like you are actually losing data, which is sort of true. But the tools that we will use actually makes it easy to maintain the structure of the program, which I will talk about next week when talking about the Abstract Syntax Tree.
Types of CFG Parsers
There are are few different types of CFG parsers; General Parsers, Top Down parser, and Bottom up Parsers.
General parsers can parse any GFG, but they are incredibly inefficient for production use, so I will not say much more about them.
Top down parsers start at the start symbol (S in my math example above) and moves towards the leaves (or terminal symbols)
Bottom Up Parsing, is what I did in the example above. It starts at the leaves (terminal symbol; NUMBER above) and moves towards the root. It is exactly what I did above: I started with NUMBER and reduced it to math and kept going until it hit S.
Top Down and Bottom Up parsers are what we use to build language parsers, they are not general parsers so you have to define a grammar for them and that is why we use tools like Bison or Yacc to generate these for us. Furthermore, we can actually break them down into different types of parsing: LL, LR, SLR and LALR. These are a bit complicated to explain here, but here is a link to the wikipedia page. If you are curious, the parser we are going to use is a LALR bottom up parsing. This is what powers YACC.
Opening PLY
Finally, we will get the meat and potatoes of describing a grammar in python for Arbor.
You should already have PLY install and defined the lexicon of the language. If you haven’t go back and read my post on the lexer If you want to skip ahead and see what the “final” parser looks like, go to my github repo for arbor.
The first thing we have to do when defining our parsing rules is to import yacc and the lexer tokens into our parsing file. We do this so that the parse understands our tokens. So far your parser file should look like this:
import ply.yacc as yacc
from src.lexer import tokensNext I define a start symbol. Admittedly, I did this because I forgot what the default start symbol is in Ply. That is really as easy as just doing start = 's'.
At this point your code should look like this:
import ply.yacc as yacc
from src.lexer import tokens
start = 's'Now we can get started on our parser rules. Ply actually makes this incredibly easy.
To define a rule, all we have to do is define a function that starts with p_ and takes in a single parameter p. Then we define a docstring (similar to the token functions in the lexer) that defines the rules. For example, here is what a function that defines one of our math rules from the earlier example would look like:
def p_mathAdd(p):
'''math : math '+' math'''
passThis is exactly equal to math -> math '+' math.
Yacc will take all of the functions that are prefixed with p_ and generate your LALR tables for you. This makes the parsing so easy on you.
Now to design your language, first you have to keep in mind the structure. I like to break down my rules are generally two types: statements and expressions. I define an expression as a statement that returns a value. So an expression is a type of statement. From there I define my expressions. Most things in arbors are actually expressions from this. I think the only things that are pure statements are my @module @use, and if/else constructs. Everything else is an expression.
Now of course my program is really just a collection of the different types of statements. So the first few rules I define are:
def p_start(p):
'''s : statements'''
pass
def p_statements(p):
'''statements : statements statement'''
pass
def p_statement(p):
'''statement : expression SEMICOLON'''
passAs we recall, I define s as my starting symbol. So s can be transformed into statements. Then statements is really just a combination of statements and statement. Finally statement is an expression with a SEMICOLON. SEMICOLON is a terminal symbol that I defined in me lexer that is, well, a semicolon.
Then I defined expression as a majority of my language. An expression are things a variable name, mathematic expression, function definition, function call, etc. Here is how I define my mathematical operators:
def p_bin_op(p):
'''expression : expression PLUS expression
| expression SUB expression
| expression MULTI expression
| expression DIV expression'''
pass
There are two ways you can combine two rules that reduce the same rule. One way, which may be easier to construct your AST, is to define them as separate functions. The above function could also be written as:
def p_add(p):
'''expression : expression PLUS expression'''
pass
def p_minus(p):
'''expression : expression MINUS expression'''
pass
...Or you can combine them in a single function, separated by a pipe (|). It really comes down to how you like to do things and your personal preferences. I often use both methods, depending on what I am trying to achieve.
Accessing Values on the Parser
You may have noticed that you pass in a single parameter p into the parser functions. This p object is the parser object. Using this object you can access the values of the expression that the parser is currently on.
You access this kind of like a list, where p[0] is the value you want the left hand expression to have (the part before the colon). If you have this rule: expression : NAME, p[0] refers to expression. After that, p[1] to p[n] refers to everything after the colon in order. In this rule: expression : NAME PLUS NAME, p[1] would refer to the first NAME, p[2] refers to the PLUS and p[3] refers to the second NAME. You would assign what you want expression to equal. For example, in the above rule, you may want expression to equal to the sum of the two values. That would be done like this: p[0] = p[1] + p[2]. Notice you don’t return! Instead you just assign p[0] to equal what you think it should return.
Note on errors:
You can handle parser errors by defining a p_error function or by using the error symbol. The parse object will have line number, but not column number, so you will have to figure that out. I wrote a function to do that that looks like:
def find_column(input, token):
last_cr = input.rfind('\n',0,token.lexpos)
if last_cr < 0:
last_cr = 0
column = (token.lexpos - last_cr)
return columnIf p is none, that means you hit the end of the file unexpectedly.
Actually Parsing
When you are done defining your rules, you need to instantiate the parser. This is very similar to how the Lexer is instantiated: parser = yacc.yacc(debug = True). You don’t need debug=True although it definitely helps for debugging. After that, the parser object has a method called parse. You pass in the string you want to parse into this method and the parser will get to work. This method returns the value that was assigned to p[0] in the entry node. For me this is where I do s : statements, but it could be wherever your start symbol is.
The wrap up
That’s all there is really to parsing. Parsing is a major part of building a compiler, and the concepts employed in computer language parsing can be used anywhere!
Lexing and Parsing really are the easy part of building a compiler. The fun parts come next: the AST and converting Arbor to LLVM bytecode. That is what I will talk about in the next post!
By the way, I would like to point out that I am a few weeks ahead in building the compiler for Arbor. I am a bit sloppy with my code right now for the Arbor compiler and all of my stuff is in the parser branch (even though it should be broken down better). If you want to look at the latest and greatest, look at that branch!
As always the link to the Arbor project is here: https://github.com/radding/Arbor