Building Production Code
Posted on Oct 28th, 2017 in Engineering
Last Tuesday, I gave a talk on building production code for Michigan State’s Spartan Hackers. In a bit of a departure from my retro theme, I am writing about building production code
Last week, I gave a talk at Michigan State’s Spartan Hackers. The topic of the talk was building production level code. This is something I have noticed many beginner programmers struggle with from all walks of life. Computer Science graduates, Bootcampers, and self taught programmers all struggle with these concepts when they are just beginning. This was the inspiration behind this talk and I hoped to shed some light on what it takes to build professional level applications.
First, a Story
This is the story of LykeMe, the first startup I built in college.

LykeMe was really fun to build, both as a business and as a product. We won some pitch competitions, went to Techweek Detroit and Techweek Chicago in 2015, and got a lot of great press. We were featured in Cosmopolitian magazine, Self magazine, Inside Higher Ed, USA Today and many other small blogs.

It was an incredible journey that culminated in us getting tens of thousands of users. At one point, I personally managed a team of five. This was the first time I was responsible for building a product from start to finish. To say I learned a lot would be an understatement.
So What Did I Learn?
This biggest thing I learned was about scalability. At this point, most of my peers will roll their eyes and quote (wrongly) Donald Knuth: "premature optimization is the root of all evil." But just hear me out.
When the topic of scalability, everyone immediately thinks about making sure your application doesn’t fail for a ton of users. But that is really only one type of scalability. There are really two types of scaling; the first of which is the one everyone thinks about, scaling with your user base, but the second, less talked about, but arguably more important form is scaling with your code base and your team. Actually, that’s not really true. Both are important, but properly scaling your code base and processes to accommodate a larger team and much more code really feeds into scaling an application to support more users.
So how do you scale?
There are some differences between the two parts, but the one, very important, similarity that is really what this post is all about is architecture.
A well architected solution is the difference between the Burj Khalifa and a house of cards. Good code is well architected. Just read this quora question about hiring a programmer who takes three hours vs one that takes twelve, and you’ll quickly see a recurrring theme. Everyone wants to hire a developer who takes his time to write well structured and clean code. None of that would be possible if the programmer didn’t take into account architecture while building his solution.
MSDN (for those who don’t know, MSDN stands for Microsoft Developer Network) defines architecture as the process of defining a structured solution that meets all of the technical and operational requirements, while optimizing common quality attributes such as performance, security, and manageability. It’s the second part of this sentence that is the most important part, "optimizing common quality attributes such as performance, security, and manageability." Optimizing performance means that your application handles large loads seamlessly, and optimizing manageability means that your code base can handle as many hands and change as easily as possible no matter the size of your code base or team. This is why the many answers on the Quora question above prefered the developer who took a long time over the developer who took little time, the simply produced better architected and hence more manageable code. But manageable code also makes it easier for your application to tackle hopefully increasing traffic, as your code will be much easier to modify when you recognize a piece of code isn’t performing well.
Additionally, architecture also feeds into your infrastructure. If you have a ton of microservices, you will probably have a ton of servers that host each individual service, or a container for each service. Each service has it’s own load balancer, application servers and database servers. But if you are doing a monolithic service, you would probably have one proxy server, one application server, and one database server at the minimum. Different architectures require a vastly different infrastructure setup.
Architectural Styles
Now that we spoke about why architecture is important and what it is, let’s talk about what an architectural style is. An architectural style is really just a reusable solution to common problems. This is an important concept because it will prevent you from "re-inventing" the wheel every time. Some of these styles are well known, such as everyone’s favorite laid out in Roy Fielding’s dissertation, Architectural Styles and the Design of Network-based Software Architectures, REST (Quick side note: REST and SOAP are usually compared, but in reality, they are not comparable and you should read Fielding’s dissertation and this, much shorter, stack overflow answer to learn why!)
Why is it important for software designers to focus on architectural styles? Well most of the problems we face are the same thing posed in many different ways. Take for example authentication for service. A logical way to perform authentication would be to route all application traffic to a single point, check for authentication, pass traffic that passed that check on to the next part of the service and reject all traffic that doesn’t. Now think about an application that searches for a process matching a certain pattern. On Linux and MacOS, you would use ps aux to see a list of all running processes. You could also use grep -i <pattern> <input> to search input for pattern. In order to search all running process for a given pattern you would run something like ps aux | grep -i <pattern>. That mean you take the output from ps and put it in the input for grep.
Now, authentication and searching for a process may seem like completely different problems, but in reality, the way I presented them, they are leveraging the same architetural style, Pipe and Filter!. In fact, the Pipe and Filter architecture is one of the things made the Unix family of OSes so popular. Things like this happen all over the place; two seemingly unrelated problems share a common trait that allows them to both use the same architectural style.
But none of this to say is that one architectural style is better than the other or "right" for this domain of problems. Two different people will come up with different architectures to solve the same problem and both of them are probably right. For example, I may want to implement authentication as I described above and you may want to implement authentication as a layered system where every service is responsible for checking the authentication itself. Both ways are completely valid, and depending on your application, one may be preferable to another.
Finally, it should be noted that architectural styles are NOT exclusive. Just because you chose a Pipe and Filter architecture for authentication, that doesn’t mean you can’t use REST for everything else. And just because everything else in your app uses REST, that doesn’t mean you can’t use another completely weird style for some aspect of your service. Different problems will need to be addressed differently, and any big piece of software is really just a massive collection of different problems. And if you look at chapter three of Fielding’s dissertation, you will find tables that describe the trade offs between different architectures.
So how do we "architect"?
In order to build a well architected solution, you need to know a few things. The first is IT infrastructure and budget. If you have a few hundred dollars, you won’t be able to build an awesome microservice infrastructure on AWS. The second is understanding the overall problem you are trying to solve. This is otherwise known as understanding the business case behind the service. Another "good idea" is to design something to change. And the final big thing to understand is really your language and technology well.
IT infrastructure and budget
I know I said earlier that architecture feeds into infrastructure, and that is still true. But you may face limitations with your current infrastructure that puts some architectural ideas way out of reach. It’s kind of like building an airplane; you can do it, but if you don’t have a run away or a place to test it, it was just a waste of time and money.
However, today lacking IT infrastructure has been greatly reduced thanks to services like Amazon Web Services (commonly referred to as AWS), Google Cloud platform, Azure, and Digitalocean, but budget could still be a problem. AWS could be to expensive for smaller projects. A small client of mine was once paying thousands of dollars on to host their application because a previous developer went and built this beautiful microservices architecture that was really designed for a large team and "infinite" scalability. Obviously, the client could save money by switching to a less elegant but still good monolithic architecture, especially with the load they were experiencing. It’s like the Rolling Stones: No, you can’t always get what you want.
Understanding the overall problem
A great example of this comes from when I was working on LykeMe. If you don’t know, LykeMe was a social media application that matched people in the same area based on shared interests. The way matches would need to work is find everyone in the area, find what they have in common, and divide it by what they don’t have in common, then store these matches in a database, sorted by that result. What I did initial was have an API endpoint that would run all of the matches for a given user, and a separate on that would run all of the matches for every user. If I had 100 users, than 1 user had to match to 99 other users. I had 100s of times this many users. Of course that didn’t mean I had to match 1 user to 10,000 other users, because it was only supposed to match people in the same area. My most dense area still had thousands of users though and way too many matches to perform on a single request. A single request to match one user could take a while (I think it was close to one minute, but don’t quote me on that!).
Any way, that is a classic example of not understanding the problem. Had I properly understood combinations and the matching logic I would write, I probably would have designed it in such a way where the endpoints will put the matching request into a queue and have a separate queue worker would actually perform the matching. Of course I understood that it would be a computationally heavy task when I wrote it, but I didn’t understand it would be that heavy. In retrospect, it was a boneheaded move, and a lesson well learned.
It is absolutely vital to understand your problems in order to creating great applications. I can not recall how many times my "beautiful" architecture changed because of new information on how the application will be used. You need to build to meet the requirements of the application, otherwise, what are you building? Some aspects of the solution may be better suited as a separate system, or may absolutely needed to be separate system, just like in my example above.
Understanding your technology
If you google "language X vs language Y" you’ll get millions of results that says things like "Language X is better than Y because Y sucks." That is basically what the argument of why a language is better than another for many people. For example: "Python is better than JavaScript because JavaScript sucks!"
This is complete bullshit. This is something that I see most entry level engineers do as well, I have even seen some professional engineers with tons of experience engage in this kind of behavior. And to be honest, none of it matters. You can use any language or framework you want to, for whatever reason. The only two reasons to use one language over another in most applications is A) you know that language well, or B) you want to learn that language. That is it.
The reason I am saying this is because shitty code is shitty code. The worst code in C/C++ will underperform against the best code in Python. And shitty code comes from not understanding your technologies well!
Each language has its own strengths and weaknesses. You must design your application’s architecture to strengthen your chosen language’s strengths and to downplay its weaknesses. The way you would build a Node.js application is somewhat different than how you would architect a Python application. Trying to shoehorn the same exact architecture decisions that you made in Python to a Node application will honestly frustrate you. Don’t do it. Learn the languages commonly accepted best practices, learn the quirks of the language, and build your solutions to unleash the language’s and technologies full power. But be careful not to go overboard.
A word on Architecture and Software engineering
A lot of this post has been focused on really broad architecture principles. I won’t blame you if you said "I want to be a software engineer, not a software architect!" But I firmly believe that a software engineer needs to be aware of the architecture of the system and even needs to do a little architecture at their level. Take a look at the career path of a software engineer:
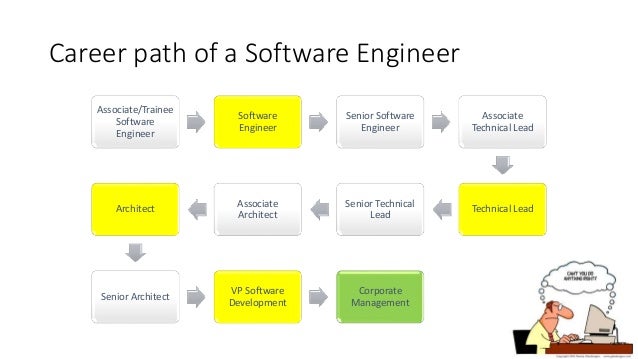
The architects sit at the top. They design the overall system. They decide the layout of the servers, the placement of certain servers, the way each component interacts with each other, etc. The next level guys get handed the components the software architects thought of. These guys could be lower level architects or maybe team leads. They design how the internals of their own service ought to behave. They make similar decisions to the architects, just on a much smaller scale. Again, the individual components are broken up and the tasks divvied up to the next lowest level: the software engineers. They are tasked with building the component that their manager assigned to them. They have to design an interface, build it in such a way that is manageable, build the interactions in such a way that it meets the requirements as laid out by their team lead. In other words, many of the decisions made by software engineers are the same decisions as the decision made by their team lead, which are the same decisions made by the architects, just at a smaller scale.
You may point out that software engineers focus more on design patterns. And I will agree on that, with one additional adage, I don’t really see a difference between design patterns and architectural patterns. They solve many of the same problems just on different scales. Design patterns focus on solving recurring problems in software construction, while architectural patterns really solve recurring problems in software system construction.
The close out
If you keep architecture in mind while building anything, chances are you will build great code. Of course you still have to balance out and be careful of over engineering. As Donald Knuth said, "premature optimization is the root of all evil." I should point out that this doesn’t mean to ignore any and all optimizations and just do some cowboy coding. The full quote is "We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil." Do what you can to make great code, but don’t yet worry about the really obscure edge case that will cause your code to fall apart and force you to rebuild using different architectures and design patterns. If you do try to solve that edge case right away, you will spend to much time building something, and have effectively overengineered your solution, resulting in wasted time. It is a balance between designing good code, and designing overkill code. I myself am guilty of writing overkill code, even to this day.
Thanks for reading and if you have any questions, want some clarification on this post, or want to talk about architecture, feel free to contact me. You can shoot me an email to my email address listed below, or send me a message on twitter.